RAG Isn’t Magic. It’s Damage
Control for LLMs (And That’s a Good Thing)


Feb 4, 2026
➽ Introduction
LLMs are impressive right up until you ask them a simple business question:
“What does our contract say about refunds?”
Suddenly the model hallucinates, hedges, or confidently gives you something that sounds right but is legally wrong.
That failure is not a bug. It’s the default behavior of LLMs.
This is exactly why RAG exists.
➽ Why LLMs Break in Real Businesses
Large Language Models do not “know” your data.
They don’t have access to your internal documents. They can’t read your PDFs, tickets, or Notion pages. And they will happily guess if the answer feels statistically likely.
This creates three very real problems in production systems:
- Wrong answers delivered confidently
- Manual copy‑paste workflows to help the AI
- Zero traceability of where answers come from
If you’ve ever thought, “The model is smart but useless for our actual work,” you’ve already hit the wall RAG is meant to fix.
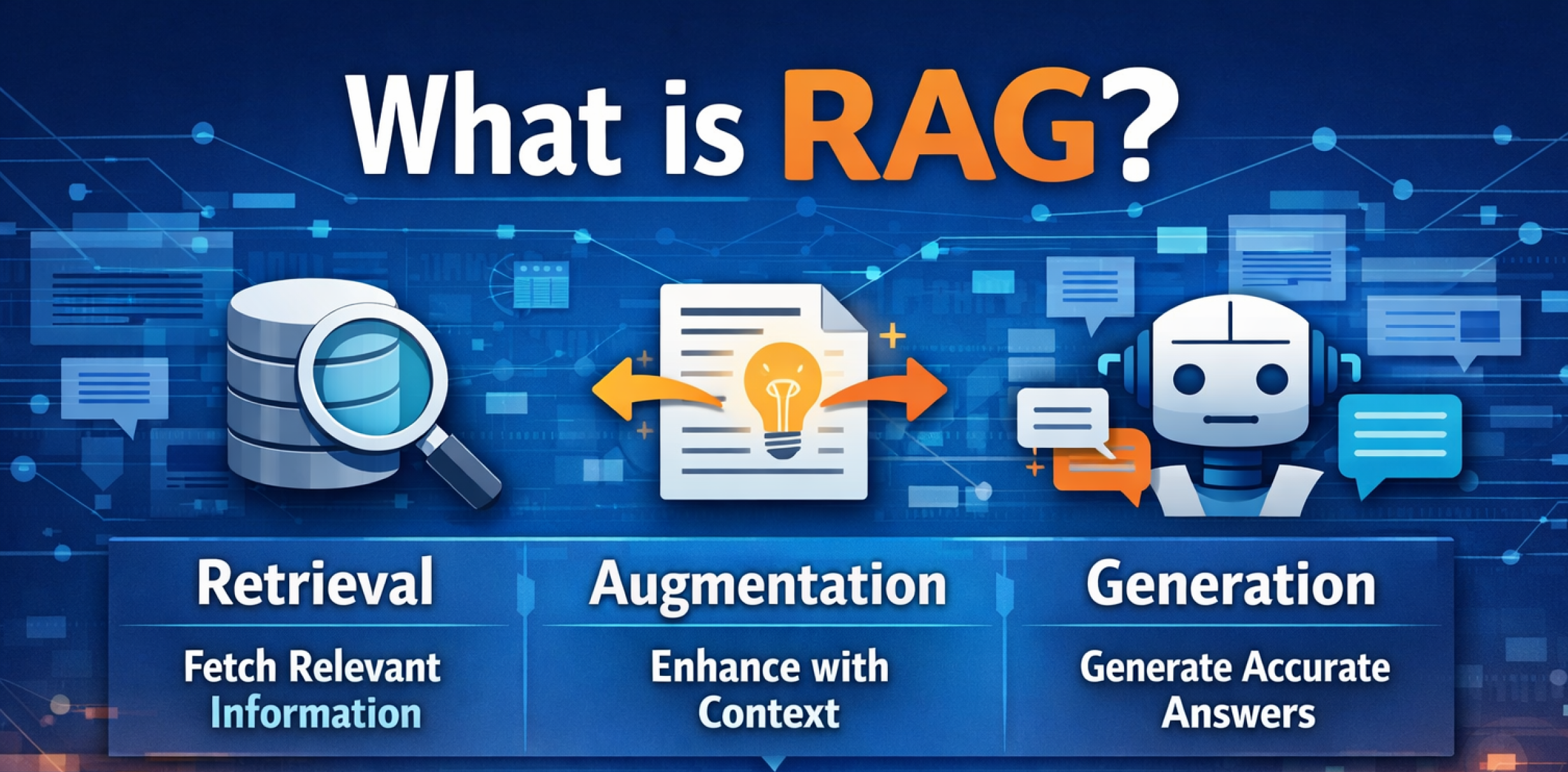
➽ What RAG Actually Is
Retrieval‑Augmented Generation is a simple idea dressed up with a scary name.
Instead of asking the AI to answer from memory, you:
- Fetch relevant information from your own data
- Give that information to the model
- Ask it to answer using only that context
So the model stops guessing and starts grounding its answers in your data.
A mental model that works well is this:
RAG turns an LLM from a confident guesser into a very fast reader.
No magic. No new intelligence. Just better inputs.
➽ What RAG Is NOT (This Matters)
This is where most blogs quietly mislead.
RAG is not fine‑tuning. It is not a chatbot that magically understands your database. It does not fix messy, outdated, or incorrect data. And it is not a one‑time setup you build and forget.
If your documents are wrong, RAG will return wrong answers faster.
If your data is unstructured chaos, RAG will politely serve that chaos back to users.
RAG does not make bad systems good. It exposes them.
➽ When RAG Makes Sense (And When It Doesn’t)
➧ RAG works best when:
☑ Knowledge lives in documents like PDFs, SOPs, tickets, or internal wikis
☑ Humans currently search or ask other humans for answers
☑ Answers need sources, references, or citations
☑ Data changes often but retraining models is expensive
➧ RAG is a poor choice when:
☒ Data is tiny and mostly static
☒ Workflows are fully transactional, like payments or ledgers
☒ You need strict real‑time guarantees
☒ You don’t control or trust the source data
Using RAG where it doesn’t belong creates systems that look smart in demos and fail quietly in real usage.
➽ How RAG Helps Businesses (Real Outcomes)
Forget buzzwords. Here’s what actually improves when RAG is implemented correctly.
Support teams stop answering the same questions repeatedly. Internal docs and past tickets become a searchable knowledge base. Response times drop. Escalations reduce. New hires ramp faster.
Sales teams stop guessing. Reps get grounded answers pulled from pricing docs, feature matrices, contracts, and policy documents instead of Slack threads.
Operations teams retain institutional memory. Processes no longer live only in people’s heads. When someone leaves, knowledge doesn’t disappear.
Compliance and audits become easier. Answers can include source documents, page numbers, and version references, saving weeks during audit cycles.
➽ A Simple RAG Flow (No Code, No Mystery)
A typical production RAG system follows this flow:
- Documents are broken into chunks
- Each chunk is converted into embeddings
- Embeddings are stored in a vector database
- A user question comes in
- Relevant chunks are retrieved
- The LLM answers using only that retrieved context
If someone explains this in twenty steps, they are either selling something or hiding confusion.
➽ Why Most RAG Projects Fail
Most RAG implementations fail for boring reasons.
Teams dump raw data without cleaning it. They chunk blindly without understanding the content. They never evaluate answer quality. They skip feedback loops. And they treat RAG like a demo instead of infrastructure.
The model is rarely the problem.
The pipeline is.
Good RAG systems are boring, disciplined, and opinionated. Bad ones look impressive on day one and collapse under real users.
➽ The Real Takeaway
RAG doesn’t make AI smarter.
It makes AI honest.
Honest about what it knows. Honest about what it doesn’t. Honest enough to be useful in real business environments.
If you treat RAG as a feature, you’ll be disappointed. If you treat it as infrastructure, it quietly becomes one of the highest‑ROI AI investments you can make.
That is the difference between a chatbot and a system people actually trust.












